

Comprehensive Audio Processing Solution - Cancelation, Separation, Equalization, Improvement
With the widespread adoption of the Internet and 5G infrastructure, video consumption represented by live and vod has become an integral part of people's daily lives. More and more users are watching videos for entertainment and learning, and excellent audiovisual quality has a crucial impact on the viewing experience. On the one hand, people want high-quality video in these scenarios. On the other hand, a better auditory experience is also indispensable, including less noise interference and more stable audio loudness. Tencent Cloud Media Processing Service (MPS) already covers video, audio, and subtitles, and its audio processing capabilities are constantly evolving to help live, vod, and other businesses achieve the ultimate audio experience.
The Composition of the Audio Processing Solution
Currently, Tencent MPS audio processing capabilities are mainly divided into four parts, covering noise cancelation, audio separation, volume equalization, and audio improvement. Each audio processing capability can independently enhance audio for different application scenarios and practical needs, or they can be combined to comprehensively process audio streams under complex requirements, thereby improving the overall auditory experience.
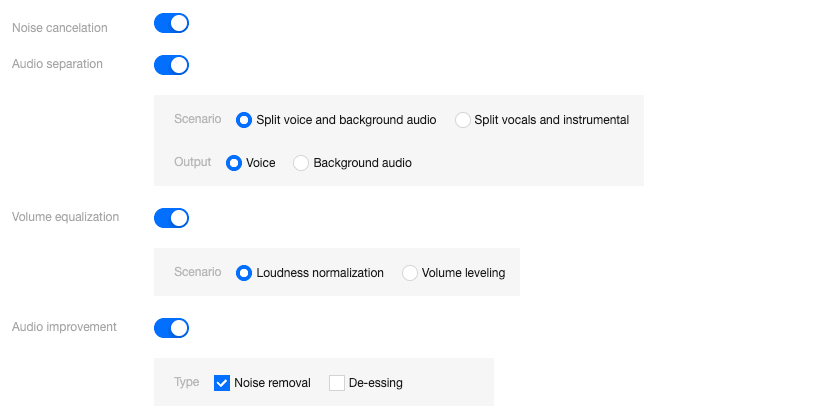
MPS Audio Enhancement Template
Noise Cancelation
Traditional noise cancelation solutions based on signal processing methods can only handle stationary noise to some extent, while they have little effect on transient noise. To address this, Tencent MPS has developed an AI-based noise cancelation solution. Based on a large amount of clean speech data and real noise data, the noisy speech signals under different environments and different signal-to-noise ratio conditions are simulated by randomly mixing clean speech data and noise data. In this way, a supervised learning method is used to train a powerful and generalized speech enhancement and denoising model. Tencent MPS's noise cancelation solution has the following characteristics:
- Supports up to 48kHz sampling rate for full-band signal denoising. This solution is suitable for various common sampling rate signals, such as 16kHz, 32kHz, 44.1kHz, 48kHz, etc. For audio signals with an original sampling rate lower than 48kHz, denoising processing through upsampling will not result in bandwidth loss.
- Supports denoising tasks for multiple languages and noise types. Our training set mainly includes Chinese and English, along with clean speech data in multiple languages such as Russian, French, German, Spanish, and Italian. We use a large noise dataset, including various common noise types in outdoor and indoor environments. The model has strong generalization and robustness, suppressing noise interference while ensuring the integrity of the target human voice.
- Supports controllable noise suppression strength. This solution can quantitatively suppress noise components in noisy speech according to actual needs, such as improving the signal-to-noise ratio of noisy speech signals by 10dB. This feature can smoothly reduce background noise intensity and highlight speech signal components. After processing, the audio signal retains the original environmental characteristics while improving speech intelligibility and fluency.
Case Study of Noise cancelation:
Noisy Environment | Before Processing | After Processing |
Outdoor Noise (Natural Wind Noise + Bird Chirping) |
| |
Indoor Noise (Microphone Hissing + Background Voices + Constant Noise) |
Case Study of Controllable Noise Reduction:
Before Processing | |
Weak Noise Reduction | |
Relatively Weak Noise Reduction | |
Strong Noise Reduction | |
Intense Noise Reduction |
Audio Separation
The goal of audio-denoising tasks is to recover a cleaner speech signal from a mixed audio signal contaminated with noise. Audio separation tasks are similar, aiming to extract the target signal components from the mixed audio stream, but the target components are not limited to a single speech signal. Tencent MPS has designed an AI-based audio separation solution. Tencent MPS's audio separation solution has the following characteristics:
- Supports general noise reduction function. This solution can extract the human voice component from the mixed audio signal, which is equivalent to conventional speech denoising schemes, and can separately isolate the background noise component in the mixed signal, which is helpful for noise analysis.
- Supports separation of audiobooks, movie and TV drama lines, and background sounds. This solution can separate speech and various background sounds, and both the speech component and background sound component have high fidelity, suitable for secondary creation.
- Supports song accompaniment separation. This solution can separate the vocal part and BGM of a song and further separate the BGM part into different instruments, obtaining bass and drum tracks, which can be applied to karaoke or remixing scenarios.
Separating Voiceover and Background Music in Film and TV
Before Processing | Vocal Separation | Background Sound Separation |
Separation of Song Accompaniment
Before Processing | Vocal Separation | Background Sound Separation |
Volume Equalization
In live and vod scenarios, we need to use adaptive volume equalization algorithms to automatically adjust the loudness of audio streams, stabilizing them within an appropriate range and enhancing the user's auditory experience. Tencent MPS has developed a volume equalization solution based on automatic gain control algorithms and the EBU R.128 audio loudness standard, which can solve issues such as volume being too large, too small, or fluctuating. The volume equalization solution has the following features:
- Supports automatic adjustment of audio file overall loudness and dynamic range. In video-on-demand scenarios, this solution can perform loudness normalization processing on audio based on the EBU R.128 standard, ensuring that the overall loudness, peak loudness, and dynamic range meet output requirements.
- Supports real-time volume adjustment. With a minimum latency of 10ms, it dynamically adjusts audio loudness, reducing sudden volume changes and stabilizing the loudness of the audio stream.
Case Study of Volume Equalization:
Volume issues | Before Processing | After Processing |
Volume too high | ||
Low volume | ||
Volume fluctuates |
Audio Improvement
In live and vod scenarios, there may be impulse noise and popping sounds caused by microphone malfunctions, network transmission packet loss, discontinuous audio frame processing, etc. These types of audio faults can also negatively impact the listening experience. Therefore, Tecnent MPS has developed a noise detection and repair technology that can diagnose audio streams in real-time, determine whether there is noise interference, and automatically repair faults to restore high-definition audio. For speech signals, Tencent MPS has developed a sibilance suppression solution that can beautify the hissing sound caused by high-frequency airflow, improving the quality of speech perception.
Case Study of Audio Restoration and Improvement:
Types of audio Improvement | Before Processing | After Processing |
Noise removal | ||
De-essing |
The Advantages of MPS-Based Audio Denoising
Tencent MPS has achieved significant advantages in audio-denoising technology due to algorithmic improvements. By proposing new solutions based on MPCRN and VSANet, the algorithm has been refined and enhanced, resulting in a more efficient and effective noise reduction approach. These advancements not only maintain the integrity of the original audio but also provide a competitive edge in delivering high-quality audio experiences across various scenarios, such as live streaming and video-on-demand services.
Conclusion
This article mainly introduces the audio processing capabilities of Tencent MPS. In fact, we have a deep technical accumulation in the field of audio processing, having published numerous academic papers and technical invention patents. Regarding the future development prospects of MPS, we have the following considerations:
- The concept of technology serving the product: All technical research serves the product. MPS will continuously refine audio processing-related technologies in the process of serving customers, aiming to become a media processing product that is more closely aligned with user needs.
- Maintain sensitivity to new technologies: Continuously enrich the MPS audio processing capability matrix, providing customers with more tool choices for their audio issues, and bringing better and newer auditory experiences to users through new technologies.
- Enhance the universality of audio processing capabilities: Provide different optimization solutions for server-side and client-side, and try to reduce the parameter volume and computational complexity of various algorithms, thereby reducing resource consumption.
If you're interested in learning more, welcome to Try Demo and Contact Us.
MPS Audio Processing Experience Demo
