

What is MV-HEVC?
On June 6, 2023, Apple Vision Pro, which had garnered significant attention in the global tech community, was officially unveiled at the Apple Worldwide Developers Conference (WWDC). It claimed to significantly enhance the subjective and objective experience of 3D videos through hardware encoding and decoding support for the MV-HEVC coding standard. This announcement sparked a flurry of searches as many developers sought to understand what MV-HEVC is and how it differs from traditional HEVC-based 3D encoding.
Traditional 3D Imaging Technology
1. Introduction to 3D Video Imaging
Currently, commonly used 3D video imaging technologies include holographic projection, glasses-free 3D screens, and stereoscopic movie display technology.
- Holographic projection: Holographic projection is an advanced display technology that can create three-dimensional images in the air or on transparent media. This technology is based on the principles of holography, which involves recording and reproducing the interference patterns of light waves from an object, resulting in a three-dimensional image that appears as if the object is present. However, this display technology is still in the experimental research phase due to the limitations of display media and has not been commercially scaled yet.
- Glasses-free 3D: Glasses-free 3D technology is a technique that allows viewers to perceive 3D effects without wearing 3D glasses. It typically involves the use of special grating or lens arrays on the display screen, creating slight differences in the images seen by the left and right eyes, thus producing a stereoscopic effect. However, this technology requires dedicated displays and is costly, resulting in its limited popularity at present.
- Stereoscopic movies: Stereoscopic movie display technology is the earliest and most commonly used technique for creating 3D images. It involves the use of dual-color filters or polarized lenses to present different images to the left and right eyes, creating a stereoscopic effect. Viewers can experience this type of video by wearing special glasses.
- VR Headsets: VR headsets present a 3D effect by delivering separate left and right viewpoint images to the viewer's corresponding eyes. Meta Oculus is a popular VR headset device on the market, and recently, Apple has also introduced its highly anticipated Vision Pro, which is also a VR product. Apart from holographic projection technology, most other 3D imaging technologies involve presenting the left and right viewpoint videos to the viewer's eyes using different methods. Therefore, 3D videos can be seen as a combination of two separate 2D videos displayed simultaneously.
2. Primary Methods for Encoding 3D Videos
At present, VR headsets and stereoscopic movies are the most common 3D video content used. They are mainly encoded, transmitted, and displayed based on the left and right viewpoint images. However, a significant amount of 3D video content has not been encoded using specialized video coding standards but rather general-purpose video coding standards. The typical method is to merge the left and right viewpoint images into a single frame in a side-by-side (SBS) format and then encode the combined sequence.
Using the HEVC encoder as an example, it lacks the ability to search for similarities between different camera angles. This means that the left and right halves of the same frame cannot be predicted based on each other. Additionally, due to the limited range of motion estimation search, inter-frame prediction cannot make use of information between different viewpoints. Therefore, eliminating the redundant information between the left and right viewpoints of 3D videos can significantly improve the efficiency of the encoder.
What is MV-HEVC?
In response to the new features of 3D videos, especially multi-viewpoint stitched 3D videos, the Joint Collaborative Team on 3D Video Coding Extension Development (JCT-3V) was established, and in 2014, they published the MV-HEVC standard extension for 3D multi-viewpoint video coding. Figure 1 illustrates the motion vector diagram for inter-frame prediction of the right viewpoint frames encoded according to the MV-HEVC standard. It can be observed that a significant number of inter-view reference modes are utilized for the right viewpoint, effectively eliminating the redundancy between viewpoints.

Figure 1: Schematic of MV-HEVC 3D Video Coding Right Viewpoint Bitstream Analysis (Green lines with IL labels indicate inter-viewpoint references)
New Features of MV-HEVC
1. The Introduction of Layers and Changes in Reference Relationships
In the MV-HEVC (MultiView-HEVC) standard, a new syntax element called LayerId is introduced in the NALU header. It represents the viewpoint number to which the frame (or slice) encapsulated in that NALU belongs. In 3D videos, we typically use LayerId 0 to indicate that the frame belongs to the left viewpoint (main viewpoint), while LayerId 1 represents the right viewpoint (auxiliary viewpoint). Frames that belong to the same POC but have different LayerIds are referred to as an Access Unit (AU). The reference rules for encoding the main viewpoint images follow the basic HEVC standard, while for the auxiliary viewpoint, each frame is encoded based on the basic HEVC with an additional inter-view reference frame, which is the frame with the same POC in the main viewpoint. This reference structure enables inter-viewpoint referencing.
Frames belonging to different LayerIds can have the same POC (Picture Order Count) number. However, frames with a higher LayerId can reference frames with a smaller LayerId that belong to the same AU (Access Unit), as shown in Figure 2. This referencing relationship can be used in multi-layer video coding to achieve more efficient encoding and decoding.
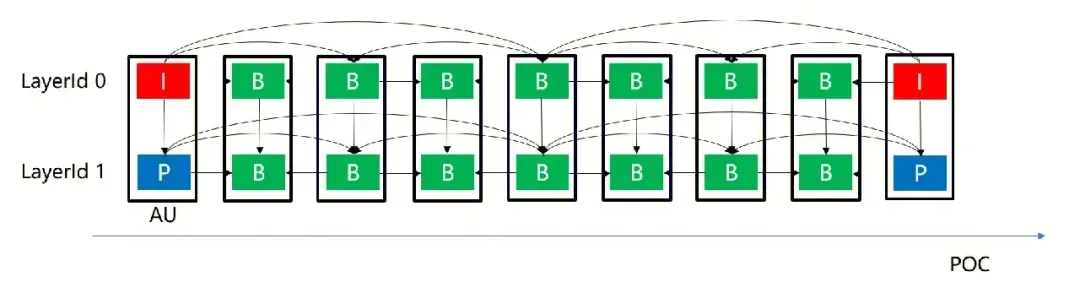
Figure 2: Illustration of Reference in MV-HEVC Dual-Viewpoint Coding
2. Changes in VPS, SPS, PPS, and Other Parameter Sets
Due to the introduction of Layers, new syntax elements need to be incorporated. Additionally, different LayerIds can theoretically serve as separate video outputs, which means they require their own SPS and PPS configurations. To address these issues, MV-HEVC extends the VPS, introduces a new Profile Tier Level, and modifies parts of the PPS and SPS syntax. Considering that a significant amount of parameter content (such as frame dimensions, chroma sampling, etc.) in SPS and PPS is redundant across different viewpoints, MV-HEVC makes special provisions for the SPS and PPS syntax referenced by frames with a LayerId other than 0, eliminating this redundant information.
3. The Introduction of Inter-Layer Mode
To eliminate information redundancy between viewpoints, MV-HEVC extends the frame inter-prediction mode to different layers, referred to as interlayer mode.
The introduction of the Inter-Layer mode brings new challenges, such as the following scenario:
TMVP (Temporal Motion Vector Prediction) mode is a frame inter-prediction technique in HEVC that selects the motion vector of the corresponding block in the current frame and scales it based on its POC distance in the spatial domain, as shown in the diagram below:
Figure 3: Schematic of Temporal Motion Vector Prediction (TMVP) Mode
The scaled and corrected motion vector (MV) is given by:
curMV = td / tb * colMV
However, with the introduction of Inter-Layer mode, it is possible for the reference frame and the current frame to have the same POC number, and both tb and td can be zero. This can result in division by zero errors or scaling to a zero vector, rendering the scaling meaningless.
To address this issue, MV-HEVC specifies that all Interlayer modes are marked as long-term reference frames, and all long-term references can only be used as long-term reference motion vector predictors (MVPs) and not as non-long-term reference MVPs. By distinguishing between inter-layer and non-inter-layer prediction modes, this prevents the occurrence of the aforementioned errors.
4. Encoding Side Testing Issues
Unlike the low-density I-frame characteristics commonly found in internet applications, the JCT3V standard, which is targeted towards broadcasting applications, typically uses an I-frame interval of 20-30 frames to evaluate the bitrate savings achieved through tool optimization. Since the layer 1 of the MV-HEVC standard does not include I-frames and instead utilizes inter-view predicted P-frames, there are significant differences in the number of reference frames used by commercial encoders compared to reference software. As a result, the compression gains of MV-HEVC achieved with reference software will be significantly higher than its benefits in internet services. Therefore, it is necessary to implement and measure the benefits of MV-HEVC on commercial encoders.
5. Decoding Side Support Status
Currently, the Apple Vision Pro chip has achieved hardware decoding support for MV-HEVC bitstreams through firmware-level optimizations. The business team can introduce MV-HEVC extended decoding capability support to their in-house HEVC decoders and adapt it to ffmpeg. This allows users to decode MV-HEVC 3D video streams by invoking the relevant decoder through FFmpeg.
Conclusion
MV-HEVC (Multi-View High Efficiency Video Coding) is an advanced video encoding technology that is an extension of HEVC (High Efficiency Video Coding). HEVC is a standard for video compression, also known as H.265, which offers higher compression efficiency and better video quality compared to its predecessor, H.264/AVC.
MV-HEVC is specifically designed for encoding multi-view videos, i.e., videos captured from different angles and viewpoints. This encoding technique significantly reduces the bitrate and storage requirements for multi-view videos while maintaining high quality. MV-HEVC has broad application prospects in areas such as 3D video, panoramic video, virtual reality (VR), and augmented reality (AR).

