

What is H.266? | Exploring Versatile Video Coding
In recent years, video formats such as Ultra High Definition (UHD), 4K, and Virtual Reality (VR) have emerged. Due to their high resolution, they are widely used in video calls and major application software, bringing people a better visual experience. However, the popularity of high-resolution video has put forward higher requirements for video compression and transmission technology. High Efficiency Video Coding (HEVC/H.265), as the previous generation video coding standard, is no longer sufficient to meet the growing demand. Therefore, a new generation of video coding standard - Universal Video Coding Standard (VVC/H.266) came into being.
What is H.266/VVC
H.266/VVC (hereinafter abbreviated as VVC, namely: Versatile Video Coding) is the latest video coding standard, proposed by the Joint Video Experts Group (JVET) on April 10, 2018. It was completed in July 2020, and then passed the first version of the International Telecommunications Union (ITU) in November of the same year. Then in February 2021, ISO/IEC also officially released its first version. Compared with the H.265 standard, the H.266 standard can achieve about 50% bit rate savings under the same subjective quality, which can then reduce transmission bandwidth, save storage costs, etc. The main target application areas of VVC include ultra-high definition video, high dynamic range (HDR) and wide color gamut (WCG) video, screen content video and 360° omnidirectional video, as well as regular standard definition (SD) and high definition (HD) video.
New Features of H.266/VVC
Different from the previous generation video coding standard HEVC, in order to improve the coding efficiency of intra prediction, VVC includes many excellent intra prediction coding tools, such as the quadtree of nested multi-type tree (QTMT) structure, matrix weighted intra prediction (MIP), adaptive loop filtering (ALF), etc. Next we will introduce them one by one.
Quadtree of nested multi-type trees (QTMT) structure
QTMT provides multiple partitioning types for block partitioning technology, namely quadrant tree (QT), horizontal binary tree (HBT), vertical binary tree (VBT), horizontal trinomial tree (HTT) and vertical trinomial tree (VTT) partitioning . The flexible segmentation method enables the VVC encoder to perform more refined segmentation according to the different texture complexity of the coding unit (CU), so that the quality of the reconstructed image during decoding is closer to the original image, thereby greatly improving the encoding performance.
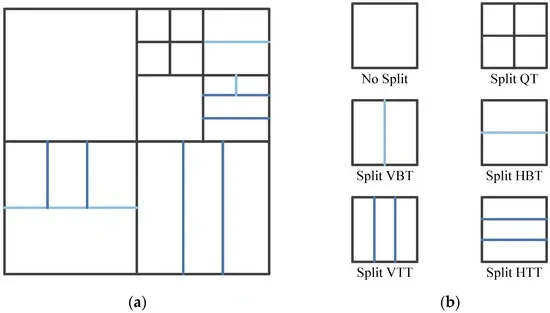
1. Initial segmentation:
The encoding process of the QTMT structure starts with the initial segmentation. First, the video frame is divided into Coding Tree Units (CTUs), and each CTU can be further divided into smaller Coding Units (CUs).
2. Quadtree segmentation:
After the initial segmentation, the CTU can be further segmented by the quadtree structure. Each CTU can be segmented into four sub-blocks to form a quadtree structure. This segmentation method can flexibly adapt to the complexity of the video content and improve the coding efficiency.
3. Binary tree and ternary tree segmentation:
Based on the quadtree segmentation, the QTMT structure also introduces binary tree and ternary tree segmentation methods. Binary tree segmentation divides a block into two sub-blocks, while ternary tree segmentation divides a block into three sub-blocks. These segmentation methods enable the encoder to adapt to the video content more finely and improve the coding efficiency.
4. Segmentation termination condition:
The segmentation process of the QTMT structure stops segmentation according to specific termination conditions. These conditions include block size, complexity of video content, and coding efficiency. By setting reasonable termination conditions, the computational complexity can be reduced while ensuring coding efficiency.
In HEVC, the coding tree unit (CTU) is split into many sub-CUs through the QT structure. Each sub-CU can be further split into one, two or four prediction units (PUs) according to the PU partition type. After predicting the PU and obtaining the residual information, the sub-CU can be further split into multiple transform units (TUs), and the division is still QT division. In VVC, PU and TU are cancelled, and the concept of CU is used uniformly. CUs can be divided using multiple partition types to obtain CUs of different sizes, which is also the biggest difference between VVC and HEVC in block partitioning technology.
Matrix weighted intra prediction (MIP)
In addition to defining the partition size, it is also necessary to define an intra prediction mode with the best rate-distortion (RD) trade-off for each CU.
Compared with the conventional intra prediction mode based on angle prediction, the newly introduced MIP mode in VVC represents another large class of new intra prediction modes trained by machine learning. Although the original design of MIP is based on providing reference samples to the neural network, it is simplified to matrix-vector multiplication due to complexity issues. Intra prediction is a key technology in video coding. It reduces redundant data and improves compression efficiency by using the encoded part of the current frame to predict the uncoded part.
MIP uses matrix-vector multiplication for intra prediction. Specifically, MIP generates a prediction signal by multiplying the boundary samples of the prediction block with a predefined weight matrix. This method can more accurately capture the spatial correlation of image blocks and improve prediction accuracy.
1. Matrix-vector multiplication:
First, extract the vector from the boundary samples of the current frame, and then multiply the vector with the predefined weight matrix to generate the prediction signal.
For a 16×16 CU, an eight-dimensional vector is formed by taking the left 16 pixels and the top 16 pixels through the domain bred averaging method. Next, multiply this vector by the matrix Ak and then add the offset vector bk, where Ak and bk are trained in advance and placed in the encoder. Finally, the predicted pixel value is obtained by linear interpolation.
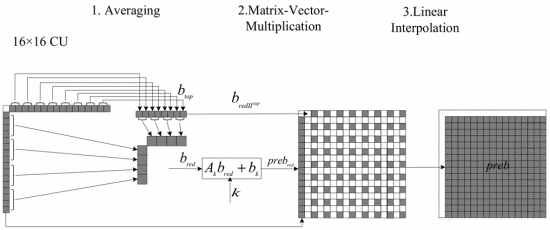
2. Generation of weight matrix:
The weight matrix is generated through offline training and is designed to capture the spatial characteristics of different image blocks. By optimizing the weight matrix, the prediction accuracy and coding efficiency can be improved.
3. Calculation of prediction signal:
The prediction signal generated by matrix-vector multiplication is compared with the actual block to calculate the residual. Then, the residual is encoded to generate the final compressed data.
Adaptive Loop Filtering (ALF)
Adaptive loop filter (ALF) is one of the loop filtering technologies of VVC, which was proposed during the development of HEVC and eventually adopted by the VVC standard. ALF is usually used to reduce the mean square error (MSE) between the original sample and the reconstructed sample.
Loop filter is an important part of the video coding standard, which can attenuate the coding artifacts produced by the block-based hybrid coding paradigm. Loop filters bring significant subjective quality improvements to the reconstructed image, and since the filters are applied in the decoding loop, they also improve the quality of the reference image, resulting in higher compression efficiency. In VVC, loop filtering consists of a fixed order chain of three filters, including deblocking filter (DBF), sample adaptive offset (SAO) filter and adaptive loop filter (ALF).
Block-based ALF is adopted in VVC, including luma ALF, chroma ALF and cross-component ALF (CC-ALF). The filter coefficients are either pre-defined and fixed in the encoder and decoder, or adaptively signaled on a picture basis using adaptive parameter sets (APS), which brings a lot of coding parameter adaptation to the ALF process. For the luma component, 16 sets of fixed filter coefficients are predefined and hard-coded at the encoder and decoder side, where each set includes 25 filter classes. At the Coding Tree Unit (CTU) level, the filter set index is explicitly signaled, and then for each 4×4 luma block within the CTU, the filter class index is derived based on the direction and activity of the local gradient. For the chroma components, a single filter set of up to 8 filters can be signaled per picture, where the filter classification method is not applied, and the filter index is explicitly signaled. CC-ALF applies an adaptive linear filter to the luma channel, and the output of this filtering operation is then used for chroma refinement. The selection of CC-ALF filters is controlled on a CTU basis for each chroma component. As with chroma ALF, up to 8 CC-ALF filters can be specified and signaled per picture.
ALF generally consists of a classification process and a filtering process. The classification process is actually a filter adaptation at the sub-block level and is applied only to the luma component. The sub-block gradient values are first calculated in the horizontal, vertical, and two diagonal directions.
The indices i and j represent the coordinates of the top left sample position in the 4×4 sub-block. As can be seen from the formula, the 1D (1-Dimensional) Laplacian values in all directions are calculated at the sample position within the 8×8 window. The following figure shows the classified sample positions of a 4×4 block. Since the 1D Laplacian value calculates the reference boundary, the entire reference block is 10×10 to classify the target 4×4 block. And in order to reduce the complexity of block classification, VVC adopts a downsampling process, which only calculates the gradient of every other sample in the 8×8 window. Then each 4×4 block is divided into 25 categories according to certain calculation rules, with corresponding filter coefficients.
After classification, the obtained ALF filter is applied to the luma component. For the chroma component, there is only one set of filter coefficients, so classification is not required. The ALF filter has two shapes, one is a 7×7 diamond for the luma component and the other is a 5×5 diamond for the chroma component, where ci represents the filter coefficient. Each square in the figure below corresponds to a sample, and the center of the diamond is the sample to be filtered.
Differences between H.266/VVC and H.265/HEVC
Coding Tools
Both VVC and HEVC coding processes are based on the well-known block-based hybrid video coding scheme, which consists of five stages: intra prediction (IP), motion estimation and compensation (ME/MC) (also known as inter prediction), forward/inverse transform quantization (TR/Q), entropy coding (EC), and loop filtering (LF).
The following figure shows the difference between the main coding tools of HEVC and VVC:
Coding efficiency
VVC is significantly better than HEVC in terms of coding efficiency. By introducing more complex prediction and filtering techniques, VVC is able to provide higher image quality at the same bitrate (Bross et al., 2021). For example, VVC's block division mechanism is more flexible and can adapt to different video contents, thereby improving compression efficiency.
Although HEVC had high encoding efficiency at the time of its release, its compression performance was relatively low compared to VVC. In the encoding of high-resolution and high-frame-rate videos, HEVC is significantly less efficient than VVC. HEVC's block division mechanism is relatively fixed, which limits its performance in complex scenes.
Video quality and distortion control
VVC effectively reduces blocking effects and other coding distortions and improves video quality through a variety of advanced technical means, such as ALF and MIP. It performs particularly well in high dynamic range (HDR) and high frame rate video coding. In addition, VVC also introduces more sophisticated quantization and transformation techniques to further improve video quality.
HEVC has relatively poor video quality at low bit rates and is prone to blocking effects and other distortions. However, by optimizing coding parameters, HEVC can still provide better video quality to a certain extent. But compared with VVC, HEVC's performance in high dynamic range and high frame rate videos is not satisfactory.
Computational complexity and hardware requirements
VVC has a high complexity, mainly reflected in its complex prediction and filtering algorithms. Nevertheless, through hardware acceleration and optimization algorithms, the actual application of VVC can still meet the needs of real-time encoding. For example, VVC's adaptive loop filtering and matrix-weighted intra-frame prediction require a lot of computing resources.
HEVC has a relatively low computational complexity and is suitable for real-time encoding on devices with limited computing resources. However, its lower complexity also limits its coding efficiency and video quality. HEVC's block division and prediction algorithms are relatively simple and require less computing resources.
Practical applications and usage scenarios
VVC is suitable for a variety of application scenarios, including high-resolution video streaming, video conferencing, virtual reality (VR) and augmented reality (AR). In these applications, VVC can provide higher compression efficiency and better video quality. For example, in 4K and 8K video streaming, VVC performs particularly well.
HEVC is mainly used for low-latency and high-quality video transmission, such as real-time video conferencing and live broadcasting. However, its low coding efficiency limits its application in high-resolution and high-frame rate videos. HEVC performs well in low-latency video transmission, but its application in high-resolution video is limited.
Compatibility Analysis
VVC and HEVC have significant differences in encoding technology and parameter settings, so direct compatibility between the two is low. VVC introduces a variety of new coding tools and parameter sets, such as video parameter set (VPS), sequence parameter set (SPS) and picture parameter set (PPS), which do not exist in HEVC.
Transcoding: Convert HEVC encoded video to VVC encoding format through transcoding technology, or vice versa. The transcoding process requires decoding and re-encoding, which may result in some degree of quality loss and latency.
Dual stream: During the video transmission process, code streams in both VVC and HEVC formats are transmitted simultaneously, and the receiving end selects the appropriate code stream for decoding as needed. This approach increases bandwidth requirements but ensures compatibility.
Adaptation layer: An adaptation layer is introduced in the encoding and decoding process to downgrade the advanced functions of VVC to HEVC-compatible functions. This approach requires modifications to the encoder and decoder, but can achieve compatibility to a certain extent.
Conclusion
As the H.266 encoding standard gradually adapts to the live broadcast environment, in order to provide a more excellent viewing experience, Tencent MPS has taken the lead in the industry to support H.266 on-demand and live broadcast services.
You are welcome to Contact Us for more information.

